Compression des images hyperspectrales
These en pdf
Chapitre 1
Contexte
HYPERSPECTRAL, compression et contraintes de l’espace, ce chapitre
présente le contexte de cette étude qui porte sur la compression des
images hyperspectrales. Dans un premier temps, nous verrons ce que sont
les images hyperspectrales, la manière dont elles sont acquises et les
contraintes spécifiques liées au traitement des données embarquées à bord
des satellites. Nous étudierons ensuite leurs particularités ainsi que les
problèmes posés par leur nature. Les notions de bases nécessaires pour
comprendre les principes de la compression d’images seront rappelées,
et enfin nous dresserons un état de l’art de la compression des images
hyperspectrales.
1.1 Les contraintes de l’hyperspectral
1.1.1 Pourquoi faire des images hyperspectrales ?
L’observation de la Terre depuis l’espace s’est d’abord faite en monochrome, principalement dans le domaine militaire avec une récupération physique des films. Les capteurs électroniques présentant des avantages évidents pour la récupération des images se sont très vite développés. Il est ensuite apparu que l’observation de la même scène à plusieurs longueurs d’onde permettait une meilleure exploitation des données. Un très grand nombre de capteurs multispectraux se sont ainsi développés, le premier étant Landsat au début des années 70. Pour permettre la formation d’images aux couleurs naturelles, l’observation est alors souvent faite dans les trois couleurs usuelles (rouge, vert et bleu) dans le proche infrarouge. Cette dernière bande est particulièrement intéressante pour l’observation des végétaux qui ont une réponse spectrale forte dans ce domaine à cause de la présence de chlorophylle.

L’évolution naturelle des capteurs d’images a conduit à l’acquisition non pas d’une, trois ou quatre bandes spectrales mais plutôt de plusieurs centaines (Fig. 1.1).
L’ajout de bandes spectrales permet d’augmenter le pouvoir discriminant des données acquises (Fig. 1.2). On peut ainsi arriver à différencier deux matériaux possédant une couleur identique à l’œil. Par exemple, une peinture verte et une feuille qui ont la même couleur, i.e. la même réponse spectrale dans le rouge, le vert et le bleu, ne pourront pas être différenciées à l’œil, l’ajout d’autres bandes spectrales permettront de faire la différence. Les images hyperspectrales tirent parti de ces propriétés. Sur la figure 1.3, rien ne retient l’attention dans l’observation des données en couleurs naturelles. En revanche, en regardant la bande infrarouge, on remarque immédiatement un point chaud qui est confirmé sur le terrain par la présence de cheminées en activité.




|
|

Une image hyperspectrale est obtenue grâce à un spectro-imageur. L’acquisition d’une même scène est réalisée dans plusieurs bandes spectrales. L’évolution entre les capteurs multispectraux et hyperspectraux suit la même logique qu’entre les capteurs monochromes et multispectraux. La différence par rapport aux images multispectrales tient au nombre important de bandes (100 à 200), à leur largeur fine (10 à 20 nm) et au fait qu’elles soient contiguës. Cette dernière propriété permet une reconstruction du spectre de chaque pixel : on réalise en fait un échantillonnage du spectre. Cet échantillonnage doit être assez fin pour permettre une bonne reconstruction. Les techniques dites de Full Spectral Imaging (FSI) devraient conduire de plus en plus à cette vision spectrale des données [Bol03]. Les sondeurs atmosphériques actuels arrivent à plusieurs milliers de bandes (2378 pour l’instrument AIRS de la NASA) on parle alors d’ultra-spectral, mais ces capteurs ne sont pas encore imageurs. Certains instruments, comme Hymap, ne conservent pas les valeurs dans les bandes d’absorption de l’eau qui sont situées dans l’infrarouge (autour de 1.4 et 1.9 μm), mais comme ces bandes contiennent plus de bruit que de signal, on peut en faire abstraction.
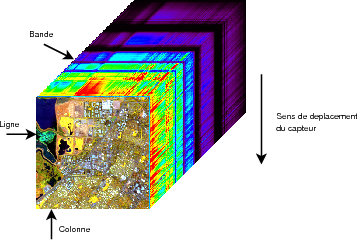
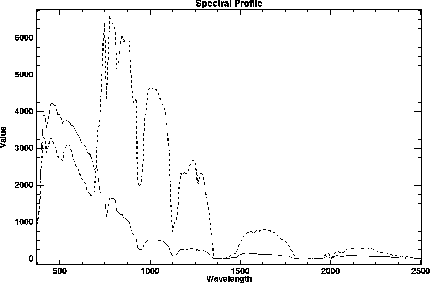
Les données hyperspectrales sont donc acquises selon trois dimensions : deux spatiales et une spectrale. Une représentation possible de ces données peut être faite sous la forme d’un cube hyperspectral (Fig. 1.4). La face supérieure du cube correspond à la scène spatiale, souvent une composition colorée de trois bandes spectrales. Toutes les scènes pour les différentes longueurs d’onde sont ensuite empilées pour donner le cube. Les autres faces du cube représentent alors respectivement les luminances, selon les longueurs d’onde (λ), des lignes (x) et des colonnes (y) en bordure du cube. Sur la droite de la figure, sont représentés des exemples de spectres des pixels de cubes extraits de l’image totale. L’abscisse correspond aux longueurs d’onde et l’ordonnée aux luminances.
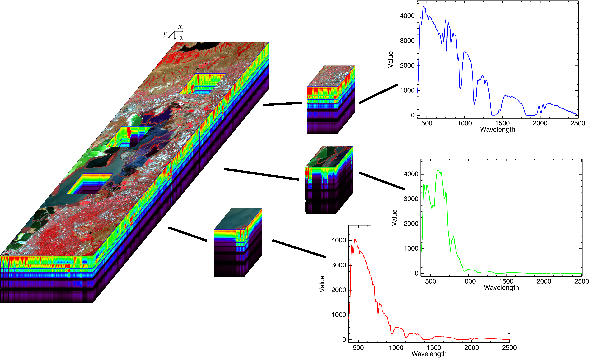
Sur la figure 1.5 (le cube de données ayant tourné pour avoir la scène spatiale sur l’avant du cube), sont détaillés les termes utilisés pour préciser la position des pixels dans une image hyperspectrale. On notera I(x,y,λ) la valeur sur la colonne x (on parle également d’échantillon ou samples), la ligne y et dans la bande spectrale λ.
Les conditions d’acquisition de ces images ainsi que les contraintes spécifiques du spatial vont être précisées ci-après, mais on peut déjà entrevoir que ces images hyperspectrales constituent un flot de données considérable à transmettre. Le but de cette thèse est de proposer une méthode de compression.
1.1.2 Acquisition des images hyperspectrales
1.1.2.1 Types de capteurs
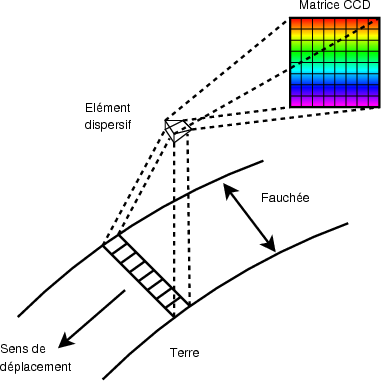
Il existe principalement deux types de capteurs hyperspectraux : whiskbroom et pushbroom. Pour échantillonner le signal reçu selon la longueur d’onde, les deux utilisent un élément dispersif : parfois un prisme, mais le plus souvent un réseau. La différence se situe au niveau de l’acquisition d’une ligne (au sens de la figure 1.5). Le whiskbroom possède une barrette CCD, où chaque élément acquiert une longueur d’onde différente. L’acquisition d’une ligne complète se fait par un système de miroir mobile pour imager une portion différente de la fauchée (largeur de l’image) à différents instants. Le capteur pushbroom possède une matrice CCD où une des dimensions correspond aux différentes longueurs d’ondes et l’autre à la fauchée de l’instrument (Fig. 1.6). L’acquisition des différentes lignes se fait dans les deux cas par déplacement du capteur.
L’inconvénient du whiskbroom est qu’il y a une partie mobile (le miroir), ce système est moins fiable dans un contexte de système spatial. Le pushbroom est plus robuste, mais produit en général des images rayées car les différentes colonnes de la matrice CCD n’ont pas toutes la même sensibilité. Ce défaut peut être corrigé en partie par étalonnage. La tendance actuelle pour les capteurs spatiaux est clairement orientée vers les capteurs pushbroom.
1.1.2.2 Dégradations typiques sur les données
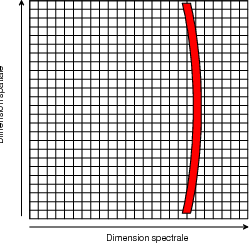
Bruit radiométrique : Comme tous les capteurs, les instruments hyperspectraux sont affectés par le bruit présent dans le signal. La valeur du rapport signal sur bruit (RSB ou Signal to Noise Ratio, SNR) permet déjà de donner une première caractérisation du bruit. Les rapports, assez faibles pour les premiers instruments hyperspectraux (de l’ordre de 50 : 1 en linéaire, soit 17 dB, pour les premières version d’AVIRIS), atteignent maintenant des valeurs plus importantes pour les capteurs aéroportés (Annexe E.2.1 : environ 600 : 1 soit 28 dB pour AVIRIS). Les premiers instruments spatiaux présentent des valeurs plus faibles (Annexe E.2.6 : de l’ordre de 150 : 1 soit 22 dB pour Hyperion). Cependant, cette valeur seule n’est pas suffisante pour caractériser le bruit. Simmons et Brower [Sim97] ont notamment étudié la corrélation du bruit entre les différentes bandes pour les capteurs HYDICE et AVIRIS. Déregistration spatiale entre bandes spectrales : Les images hyperspectrales sont a priori fortement comprimables. En effet, les différentes bandes spectrales sont très liées, la corrélation spectrale est donc importante. Cette corrélation requiert toutefois que les bandes soit registrées, c’est-à-dire que les différentes bandes soit superposables spatialement. Un même pixel sur toutes les bandes correspondra alors à la même zone physique observée. Le problème se pose surtout pour les images multispectrales dont la déregistration peut être de l’ordre d’un pixel. Dans une étude réalisée par Alcatel Space [Fra01], il a été montré que les performances de la compression multispectrale sont sensibles à la déregistration de l’image. Le gain de compression par rapport à une compression mono-spectrale devient quasiment nul lorsque la déregistration atteint la valeur de 0.5 pixels. Dans le cas des images hyperspectrales, les technologies utilisées pour l’acquisition des images sont différentes : acquisition simultanée et par le même capteur des différentes bandes spectrales. Le problème de la déregistration est donc moins important. Dans les spécifications du capteur SPECTRA, on peut voir par exemple que la déregistration pour les différentes bandes d’un même spectromètre est inférieure à 0.2 pixels. Autres dégradations dues au capteur : D’autres effets, principalement dus à la conception, peuvent affecter les instruments hyperspectraux. Le premier de ces effets est un effet appelé smile. Cet effet est provoqué par une déformation de la projection de la fente image sur la matrice CCD. L’effet au niveau de l’image se traduit par une différence d’étalonnage selon les points de l’image. Les pixels situés au centre sont normalement étalonnés, tandis qu’un décalage spectral apparaît sur les bords de l’image. Cet effet est illustré sur la figure 1.7.
Matrice CCD
|
Le deuxième effet, appelé keystone, est dû à une inclinaison de l’image d’un point sur la matrice de capteur comme indiqué sur la figure 1.8. Cet effet provoque une contamination des valeurs d’un pixel par les pixels voisins en fonction des longueurs d’onde. La dernière version du capteur aéroporté CASI est spécifiquement optimisée pour réduire ces distorsions. D’autre part, les techniques de conception actuelles pour les instruments hyperspectraux éliminent quasiment les problèmes de smile et de keystone [Bol03]. On ne prendra donc pas ces effets en compte. Dégradations après acquisition : Les post-traitements appliqués aux données causent également des dégradations irréversibles. C’est notamment le cas de la quantification, dont l’utilisation est inhérente aux données numériques. La compression, lorsqu’elle n’est pas sans-pertes, cause aussi des dégradations sur les données.
1.1.3 Espace et satellites
Les contraintes sur un système de compression embarqué à bord d’un satellite sont très fortes. Il y a tout d’abord une limitation sur la complexité des circuits électroniques utilisables en environnement spatial, des contraintes spécifiques sur l’acquisition des données et leur stockage.
1.1.3.1 Circuits électroniques pour le spatial
Compte-tenu du coût de la mise en orbite d’un satellite en orbite basse (de l’ordre de 15000 euros/kg), il y a des contraintes fortes sur le poids de l’électronique embarquée. Cette contrainte de poids est encore plus forte dans le cas des sondes lointaines. Les traitements coûteux sont effectués au sol dans la mesure du possible. La compression est nécessaire pour permettre de transmettre le plus d’information possible au sol. Dans ce cas, il n’y a pas de choix possible et le module de compression doit être embarqué.
L’énergie disponible à bord d’un satellite est également un facteur limitant. La consommation des circuits électroniques est donc un paramètre qui entre fortement en ligne de compte au moment de la conception. Les circuits dédiés de type ASIC permettent de réduire cette consommation, mais augmentent les coûts de développement.
L’espace est un environnement hostile pour les composants électroniques. Les particules ionisantes et les ions lourds qui, sur Terre, sont en grande partie arrêtés par l’atmosphère, atteignent directement les composants électroniques. Le piégeage de ces particules dans les semi-conducteurs altère leurs caractéristiques [CNE05] : apparition d’événements singuliers, SEU (Single Event Upset), ou destruction du composant, SEL (Single Event Latch-up).
Un SEU correspond à un changement de parité dans un composant mémoire ou dans un registre interne sans dommage significatif de l’élément. Dans les circuits actuels, le passage d’un ion peut affecter plusieurs bits. Ces erreurs multiples (MBU : Multiple Bit Upsets) sont plus difficiles à détecter et à corriger.
Un SEL est un phénomène qui apparaît avec certaines technologies (CMOS). Le passage de l’ion provoque un court-circuit (latch-up) ayant un effet destructif sur le composant.
Des stratégies spécifiques de développement sont mises en place pour réduire ces risques : sélection des composants les moins sensibles, durcissement aux radiations, méthodes de détection des latch-up, redondance des composants, …
Les composants électroniques homologués pour une utilisation spatiale sont relativement peu nombreux et présentent des performances bien plus faibles que d’autres composants sur le marché.
1.1.3.2 Acquisition au fil de l’eau et régulation de débit
Un satellite permet d’observer la Terre en continu. C’est un des principaux avantages de l’observation spatiale par rapport à l’observation aéroportée. Lors d’une telle observation, le flot de données en sortie de l’instrument est ininterrompu. Il faut donc commencer à comprimer les données sans connaître la fin de l’acquisition : une compression au fil de l’eau est donc nécessaire [Par03]. Le flux de données binaires issu de la compression est ensuite transmis au sol ou stocké dans des mémoires lorsque les stations de réception ne sont pas en visibilité.
Les débits d’entrée et de sortie de ces mémoires de masse est fixe. Le débit disponible pour transmettre les informations est également constant. Si le compresseur ne fournit pas un débit constant, il faut mettre en place des mécanismes complexes de régulation de débit.
1.1.3.3 Taille des images
Les données hyperspectrales sont volumineuses. Observer la même scène dans environ 200 longueurs d’onde multiplie logiquement la taille des données par 200. Le capteur spatial Hyperion acquiert en 3 secondes une scène de 7.5 × 19.8 km, ce qui représente 256 × 660 pixels dans chacune des 242 bandes spectrales. Comme ces données sont quantifiées sur 12 bits, cela représente environ 490 Mbits pour une résolution spatiale de 30 mètres seulement. Le capteur aéroporté AVIRIS présente des caractéristiques similaires. Le tableau 1.1 présente les spécifications typiques pour un capteur spatial. Les données précises concernant un plus grand nombre de capteurs peuvent être trouvées dans l’annexe E.
|
Le débit disponible pour transmettre les informations au sol est d’environ 105 Mbits/s en orbite basse, beaucoup moins pour les sondes lointaines. Comme la tendance est à une augmentation de la résolution, tant spectrale que spatiale, une compression efficace des données est indispensable.
1.1.3.4 Visibilité des stations et stockage bord
Les satellites d’observation hyperspectraux sont généralement des satellites à défilement en orbite basse. La transmission des données vers une station de réception n’est pas possible en permanence : il faut attendre d’être en visibilité d’une station. En attendant d’avoir cette visibilité, les données sont stockées à bord (Tab. 1.2).
|
La compression à bord est plus problématique que la compression au sol. En cas d’erreur, il n’est pas possible de revenir en arrière et les pertes sont irréversibles. Les contraintes qui pèsent sur les algorithmes de compression bord sont donc plus strictes.
1.2 Propriétés des images hyperspectrales
Avant de s’intéresser à la compression des images hyperspectrales, il faut bien comprendre leurs propriétés statistiques. Le fait de construire un cube avec des dimensions aux propriétés différentes (axe spectral ou spatial) va introduire des spécificités statistiques sur les données.
1.2.1 Des dimensions aux propriétés différentes
Une première manière de voir les données est de considérer chaque valeur indépendamment des autres, chaque valeur correspondant à la luminance d’un pixel pour une longueur d’onde donnée. On considère alors les trois directions comme équivalentes.
En réalité, les propriétés de ces valeurs sont différentes selon les directions spectrale et spatiales. Dans les directions spatiales, la corrélation est forte à faible distance et décroît rapidement quand le décalage augmente (Fig. 1.9 (a)). Au contraire, la corrélation spectrale est présente pour tout le spectre (Fig. 1.9 (b)). Les propriétés statistiques sont donc différentes selon la direction considérée.
La matrice de corrélation spectrale, dont l’utilité dans l’analyse des données hyperspectrales a été montrée par Simmons et Brower [Sim97], représente le facteur de corrélation entre les différentes bandes spectrales. La figure 1.10 présente deux exemples de cette matrice sur deux images différentes (le détail de ces images est donné dans l’annexe D). Le coefficient (i,j) de cette matrice de corrélation représente la corrélation entre les bandes i et j et est défini par
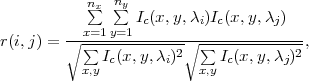 | (1.1) |
Ic(x,y,λi) correspondant à une variable centrée (donc de moyenne nulle) et nx et ny étant le nombre de colonnes et de lignes de l’image.
Le coefficient de corrélation se situe donc dans l’intervalle [-1;1], une valeur de 1 indiquant une égalité entre les deux bandes. Les valeurs étant en fait fortement corrélées, il y a rarement apparition de coefficients négatifs en pratique.
|
 (a)
(a)
 (b)
(b) Pour expliquer la corrélation spectrale, on peut remarquer que le profil spectral présente des caractéristiques indépendantes du type du terrain observé. La forme générale du spectre présentes des traits communs à toutes les zones observées. Cela est dû à l’influence de l’atmosphère (bandes d’absorption) et à l’éclairement solaire, dont l’énergie est maximale dans le domaine du visible et s’atténue dans le domaine de l’infrarouge. Ces caractéristiques modulent fortement le spectre reçu au niveau du capteur (spectre en luminance et non en réflectance).
La plus grande partie de l’énergie recueillie par le capteur se trouve dans le domaine 400-900 nm. Pour les longueurs d’ondes comprises dans le domaine d’absorption de la vapeur d’eau, l’énergie est très faible (domaines autour de 950 nm, 1130 nm et surtout 1400 nm et 1900 nm) (Fig. 1.11). A l’exception des zones de végétation, pour lesquelles on observe un pic dans l’infrarouge (à partir de 750 nm) également appelé red edge, la forme générale du profil spectral est assez semblable pour tous les pixels. L’information importante réside donc plutôt dans les détails.
|
|
 (a)
(a)  (b)
(b)
|
|
L’anisotropie des images hyperspectrales a pour conséquence qu’il peut être préférable de privilégier l’une ou l’autre des dimensions. Une première manière de traiter ces données consiste à considérer le cube hyperspectral comme un empilement d’images pour les différentes longueurs d’onde. On y applique successivement des opérations issues du traitement d’image (compression, estimation du bruit) pour toutes les images à toutes les longueurs d’onde et on combine ensuite ces résultats pour obtenir une opération globale. Cette approche est en continuité directe avec le traitement des images multispectrales.
Une deuxième manière d’aborder le problème consiste à traiter chaque pixel séparément. Les pixels sont alors représentés par une succession de valeurs représentant leur spectre. On peut alors traiter les pixels comme des vecteurs à nλ dimensions, ou bien comme un signal à une dimension (nλ étant le nombre de bandes spectrales de l’image). Des techniques de réduction de dimension peuvent être utilisées. Dans ce dernier cas, les traitements appliqués sont plutôt du domaine du traitement du signal et de la spectroscopie.
1.2.2 Problème de la normalisation
La question de la normalisation des données est aussi une question importante pour la généralisation des résultats. Classiquement, pour se ramener à une variable centrée réduite, on normalise la variable aléatoire x de la manière suivante :
![x = x--𝔼-[x-],
n σx](these17x.png) | (1.2) |
𝔼[x] étant l’espérance de x et σx2 étant sa variance.
Le problème pour l’hyperspectral est de savoir de quelle manière on considère les données. Est-ce une image (i.e. bande spectrale) pour différentes longueurs d’onde, ou un spectre pour différents points de l’image ?
Pour certains, l’image hyperspectrale est vue comme une extension du multispectral. Dans ce cas, la normalisation est effectuée pour chaque image : on calcule alors la moyenne et la variance pour les valeurs d’une bande spectrale et on normalise grâce à ces facteurs (1.2). La normalisation est dépendante du contenu spatial de l’image : le même spectre sur deux images différentes donnera après normalisation deux spectres différents. On parlera de normalisation bande par bande.
Une autre possibilité est de faire la normalisation pour chaque pixel. On calcule alors la moyenne et la variance de chaque spectre, puis on normalise par rapport à ces valeurs. Ceci correspond à une normalisation par spectre. Le spectre normalisé obtenu est alors indépendant du contenu spatial de l’image : un même spectre donnera le même spectre normalisé quelque soit l’image. Par contre, le fait de considérer ou non les bandes bruitées (de valeur faible) changera les résultats.
Une autre manière de normaliser les données, de façon à accorder la même importance à toutes les bandes par la suite, est de diviser chaque bande par sa valeur moyenne (1.3). L’intérêt de cette opération est d’équilibrer un peu la situation entre les bandes qui reçoivent peu d’énergie et celles qui en reçoivent plus selon l’éclairement solaire et les phénomènes atmosphériques.
![x
xn = ----
𝔼[x]](these18x.png) | (1.3) |
1.2.3 Un espace presque vide
Pour les applications, une image hyperspectrale est souvent vue comme une représentation des différentes réalisations d’une variable aléatoire à nλ dimensions, nλ étant ici le nombre de bandes. Les différentes réalisations de cette variable aléatoire sont les différents pixels.
Cette vision des données est intéressante pour la classification ou la discrimination. Les pixels proches (notion de distance) dans cet espace vectoriel sont des pixels semblables, la classification regroupera donc ces pixels proches dans une même classe.
Les capteurs hyperspectraux acquérant généralement de l’ordre de 200 bandes, les données se retrouvent alors représentées dans un espace à 200 dimensions. Les espaces de grande dimensionnalité posent des problèmes particuliers qui ont été exposés par Hughes [Hug68] : de tels espaces sont presque vides. En effet, en considérant des données échantillonnées sur 12 bits et acquises pour 200 bandes, il y a alors 212 = 4 096 possibilités pour chaque bande et un total de 4 096200 ≈ 10720 localisations possibles dans l’espace vectoriel de discrimination. Même avec des images de taille importante (de l’ordre de 106 pixels), la probabilité d’avoir deux pixels égaux ou voisins dans cet espace vectoriel est très faible.
D’autres problèmes apparaissent qui rendent difficile l’extension des idées intuitives en 3 dimensions. Landgrebe [Lan99] détaille une grande partie des effets provenant de ces espaces à grande dimension.
Ces considérations ont conduit à des méthodes pour réduire le nombre de dimensions. C’est le cas de l’Analyse en Composantes Principales (ACP, ou Principal Component Analysis, PCA) ou de l’Analyse en Composantes Indépendantes (ACI, ou Independent Component Analysis, ICA). Le nombre de dimensions est alors réduit à environ 10 ou 20. Ces décompositions projettent les données sur les vecteurs propres et sélectionnent les meilleurs vecteurs pour conserver l’énergie maximale. Il y a alors une perte d’information, mais ces pertes ne sont pas prohibitives pour certaines applications.
1.2.4 Une estimation de l’entropie
Dans un contexte de compression sans pertes, la notion d’entropie permet d’avoir une évaluation des performances que l’on peut espérer. Dans un message, on comprend intuitivement que tous les symboles n’apportent pas la même information. Un symbole inattendu (faible probabilité) apportera plus d’information qu’un symbole attendu (probabilité forte).
Cette notion intuitive d’information a été formulée par Shannon en
1948 [Sha49]. L’information 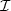 (si) associée au symbole si est fonction de la
probabilité d’apparition de si : p(si). Cette fonction F(p(si)) est définie par trois
conditions :
(si) associée au symbole si est fonction de la
probabilité d’apparition de si : p(si). Cette fonction F(p(si)) est définie par trois
conditions :
- si la source ne délivre qu’un seul message (donc une probabilité égale à 1), l’information associée à ce message est nulle ;
- en considérant si l’union de deux événements indépendants (sj et
sk), si = sj ∪ sk, avec p(si) = p(sj)p(sk), l’information (si) est
égale à la somme des informations associées à sj et sk : F(p(si)) =
F(p(sj)) + F(p(sk)) ;
- F est continue, monotone et positive.
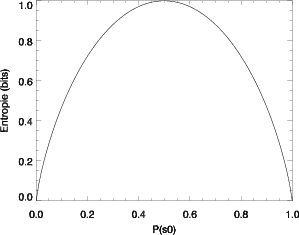
Une fonction F vérifiant ces trois conditions est -λlog(.). L’unité binaire (binary unit ou bit) choisie par Shannon est définie comme la quantité d’information contenue dans une expérience binaire équiprobable : pile ou face avec une pièce équilibrée par exemple (Fig. 1.12). Ainsi, en choisissant d’utiliser les logarithmes en base 2, le facteur λ est égal à l’unité et la quantité d’information associée à un événement si s’écrit :
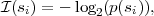 | (1.4) |
exprimée en bits.
L’entropie H(S) d’une source sans mémoire est définie par :
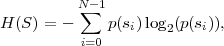 | (1.5) |
où {s0,…,sN-1} représente l’alphabet de la source.
L’entropie est une mesure de l’information moyenne de chaque symbole de la source. Elle est maximale si tous les symboles de la source sont équiprobables. De plus, l’entropie représente la longueur moyenne minimale d’un codage binaire sans pertes des données de la source. C’est pourquoi il est intéressant d’évaluer l’entropie des images hyperspectrales avant d’étudier des algorithmes de compression.
|
|
Dans un premier temps, on peut supposer avoir un modèle de source sans mémoire et estimer l’entropie des images en supposant que tous les pixels sont indépendants. Toutefois, il serait plus réaliste de prendre en compte une dépendance entre les pixels et d’introduire un modèle de Markov d’ordre 1, 2,…
Cependant, on se heurte rapidement à un problème d’estimation de probabilités. Dans le cas d’un modèle d’ordre 0, chacun des symboles est une valeur codée sur 16 bits et peut donc prendre 216 = 65536 valeurs. En effet, après calibration, les données acquises sur 12 bits sont généralement codées sur 16. Le nombre de points dans une image hyperspectrale étant typiquement de l’ordre de 15 106 (256 × 256 × 224), on peut considérer que la loi de probabilité est suffisamment bien évaluée.
Dans le cas du modèle d’ordre 1, un symbole est alors un groupe de deux valeurs : on cherche la probabilité qu’un pixel prenne une valeur sachant la valeur du pixel voisin. Ce symbole prend une valeur parmi (216)2 ~ 4.3 109. L’estimation de la loi de probabilité devient alors délicate. L’entropie a cependant été estimée jusqu’à l’ordre 3 pour donner une idée des ordres de grandeur (Tab. 1.3). Pour des ordres supérieurs, l’estimation de la densité de probabilité n’est plus possible de manière fiable.
|
Une autre manière de donner un ordre de grandeur de l’entropie (ou au moins une borne supérieure) est de tester les méthodes de codage sans pertes sans tenir compte de la nature de l’image. On utilise les utilitaires
- gzip : algorithme LZ77 [Ziv77] ;
- bzip2 : algorithme de Burrows-Wheeler [Bur94], suivi de Huffman [Huf52] ;
- ppmd : basé sur un modèle de Markov d’ordre D [Cle84], dont l’implémentation est décrite dans [Shk02].
Les performances dépendent de la façon dont sont arrangées les données (BIP, BSQ ou BIL, précisée dans l’annexe D.2) et sont présentées dans le tableau 1.4.
|
Ceci nous permet seulement de comprendre que l’entropie des images hyperspectrales est inférieure à 8.19 bits (débit minimum en bits/pixel obtenu à l’aide d’un des algorithmes de compression sans perte standard). Comme l’entropie représente aussi la longueur minimale d’un code binaire sans perte, on peut ainsi montrer que les modèles d’ordre 0 et 1 envisagés dans l’estimation de l’entropie ne conviennent pas puisqu’ils conduisent à des valeurs d’entropies supérieures à 8.19 bits. Cela conforte l’idée que pour estimer l’entropie des images hyperspectrales, un modèle de source de Markov d’ordre supérieur à 1 doit être envisagé, ce qui pose les problèmes d’estimation des probabilités mis en évidence ci-dessus.
1.3 Compression
1.3.1 Notions de base
Deux grandes familles d’algorithmes de compression existent : ceux qui peuvent reconstituer l’information exacte (algorithmes sans pertes) et ceux qui tolèrent une perte d’information (algorithmes avec pertes). Les algorithmes sans pertes paraissent préférables à première vue. En général, les images satellitaires sont complexes. Les taux de compression obtenus avec des algorithmes sans pertes sur de telles images dépassent rarement 2 ou 3. Cette limitation est due en partie au bruit introduit par les capteurs haute résolution [Aia01]. Les algorithmes sans pertes présentent donc des limitations assez importantes en terme de compression. Tolérer quelques pertes permet de dépasser ces limites. Un autre avantage des algorithmes avec pertes est qu’ils permettent en général d’ajuster le débit. Si on tolère des distorsions assez importantes, on pourra comprimer plus (débit plus faible) et inversement.
Un schéma typique de système de compression par transformée est présenté sur la figure 1.13. La quantification est une étape classique dans ce type de système, cependant, dans le cas de codage par plan de bits cette étape n’apparaît plus aussi clairement. Elle s’apparente plus à un tri des coefficients pour faciliter le travail du codeur entropique ou pour tirer parti des dépendances entre les coefficients. Ces deux étapes sont souvent fortement imbriquées et figurent donc conjointement sur le schéma. Si la transformée est parfaitement réversible, on peut obtenir un système de compression sans pertes en supprimant l’étape de quantification ou en poussant le codage jusqu’au dernier plan de bits.
|
|

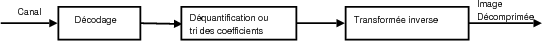
1.3.1.1 Transformée
La transformée DCT (Discrete Cosine Transform) a montré de bonnes performances pour la compression des images. Elle est notamment utilisée dans le standard JPEG ainsi que dans l’algorithme de compression embarqué de SPOT 5. Les dernières avancées montrent que la transformée en ondelettes est plus intéressante car elle supprime notamment les effets de blocs. La transformée en ondelettes est utilisée dans le nouveau standard JPEG 2000 ainsi que par le satellite Pléïades-HR, le successeur de SPOT 5.
Il existe également des transformées adaptées aux données. Par exemple, la KLT (Karhunen-Loeve Transform) consiste à projeter l’image sur ses vecteurs propres. Cette transformation est souvent utilisée pour la réduction de données hyperspectrales sous le nom d’analyse en composantes principales. L’analyse en composantes indépendantes est également utilisée. Ces transformations sont efficaces mais dépendent de l’image. Le fait de devoir recalculer la transformée à chaque image augmente considérablement le coût de calcul. Dans un contexte de compression embarquée, il n’est pas envisageable d’effectuer une KLT sur 200 bandes spectrales à bord : cela impliquerait de diagonaliser une matrice de 200 × 200 coefficients. Ce calcul n’est d’ailleurs pas envisagé à bord dans le cas d’une image multispectrale de 4 bandes spectrales [Thi06].
1.3.1.2 Codage des coefficients
De nombreux travaux ont été développés sur le codage des coefficients issus de la transformée. On peut avoir une simple quantification, de la quantification vectorielle ou des systèmes par DPCM (Differential Pulse Code Modulation). Dans le cas de la DCT, il existe par exemple un algorithme d’allocation de bits pseudo optimal [Ger92].
Pour la transformée en ondelettes, des algorithmes de codage par plans de bits basés sur des structures d’arbres de zéros donnent de bons résultats. Il s’agit de EZW [Sha93] et SPIHT [Sai96] principalement. La quantité et l’ordre des données dépend des valeurs codées. Ces algorithmes seront détaillés plus précisément par la suite.
1.3.1.3 Codeur entropique
Le principe du codage entropique est de coder les symboles les plus fréquent avec un code plus court. L’exemple le plus simple d’un codeur entropique est le codage de Huffman [Huf52].
On considère par exemple le message constitué des symboles (s0,s1,s2,s3,s4,s5,s6,s7) codés en binaire sur 3 bits (cf. Tab. 1.5).
|
L’algorithme de Huffman fonctionne de la manière suivante :
- Arranger les probabilités des symboles P(si) par ordre décroissant et les considérer comme les feuilles d’un arbre.
- Tant qu’il reste plus d’un nœud :
- Regrouper les deux nœuds avec la plus faible probabilité pour former un nouveau nœud ayant pour probabilité la somme des deux nœuds regroupés.
- Assigner arbitrairement 0 et 1 aux deux branches conduisant au nouveau nœud formé
- Parcourir l’arbre depuis la racine pour trouver le code affecté à chaque symbole.
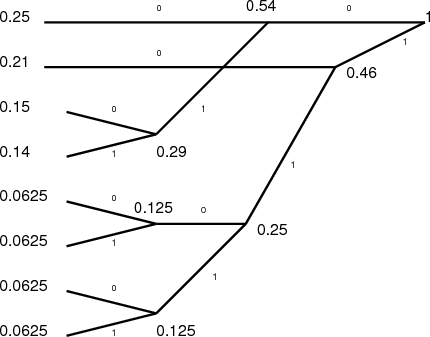
Avec l’exemple du tableau 1.5, on obtient l’arbre présenté sur la figure 1.14. On arrange les symboles par ordre décroissant. À la première étape, on regroupe les nœuds avec la plus faible probabilité, ce qui correspond aux valeurs s6 et s7. On affecte à ce nœud la probabilité p(s6) + p(s7) = 0.125 et à chacune des branches la valeur 0 ou 1. On continue ensuite le processus, qui va regrouper s4 et s5. Ensuite, les probabilités restantes sont 0.25, 0.21, 0.15, 0.14 et celles des deux nouveaux nœuds : 0.125 et 0.125. Ces deux nouveaux nœuds ont encore la probabilité la plus faible, on les regroupe donc pour former un nœud de probabilité 0.25. On continue ensuite l’algorithme jusqu’à l’obtention de l’arbre de la figure 1.14.
Pour savoir comment sera codé un symbole, on parcourt l’arbre en sens inverse (droite à gauche) pour arriver au symbole que l’on désire coder. On arrive au code final présenté dans le tableau 1.6.
|
L’entropie de ce message est égale à :
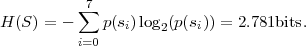 | (1.6) |
Au départ (Tab. 1.5), on avait une longueur moyenne du code qui était égale à 3. Avec le code de Huffman la longueur moyenne est passée à 2.79. Le codage de Huffman garantit une longueur moyenne comprise entre H(S) et H(S) + 1, c’est donc un code efficace. Si les probabilités sont connues, cet algorithme est optimal.
Le codage de Huffman a deux limitations principales :
- il n’est pas toujours facile d’évaluer les probabilités p(si), notamment lorsque la taille des symboles augmente (pour des symboles codés sur 16 bits, il y a 216 = 65536 symboles possibles, il faut donc disposer d’une grande quantité de données pour évaluer les probabilités) ou lorsque la loi de probabilité change au cours de la transmission ;
- la construction du code de Huffman oblige à prendre un nombre entier de bits pour coder un symbole alors que la valeur optimale pourrait être fractionnaire. Pour atteindre une longueur fractionnaire, il faudrait utiliser le théorème de Shannon du codage sans bruit et coder les extensions d’ordre supérieur de la source (grouper les symboles initiaux par 2, 3, …).
Le codage arithmétique [Ris79,Wit87,Mof98] remédie à cette dernière limitation du codage de Huffman. C’est actuellement une des méthodes de codage entropique les plus efficaces pour les données binaires. Cependant, l’implémentation matérielle du codeur arithmétique est délicate. Il n’est actuellement pas envisageable d’avoir un codeur arithmétique à bord d’un satellite. Cette situation va bien sûr probablement changer dans les prochaines années avec l’évolution des circuits électroniques.
1.3.2 État de l’art
Pour la compression des images hyperspectrales, deux grandes tendances existent : des systèmes de compression plutôt orientés vers les applications de type classification et des systèmes plus génériques [Mot06]. Les systèmes de compression orientés vers la classification sont basés sur la quantification vectorielle avec création d’un codebook. Les systèmes plus génériques sont basés sur un schéma classique de compression par transformée.
Par leur nature de données tridimensionnelles, les images hyperspectrales s’apparentent aux données vidéo et à certaines données médicales. La compression de ces données posent des problèmes semblables mais avec des contraintes parfois différentes. Par exemple, pour l’imagerie médicale, l’absence d’artefacts est une condition indispensable ; la compression des images ne doit pas pouvoir conduire à un mauvais diagnostic. En vidéo, pouvoir accéder de manière aléatoire à une partie de la vidéo sans avoir à décoder tout le flux depuis le début correspond à une demande forte. Des différences existent également concernant les propriétés à exploiter, dans le domaine vidéo la compensation de mouvements est très utilisée, ce qui n’existe pas dans le cas de l’hyperspectral.
1.3.2.1 Compression par quantification vectorielle
La compression par quantification vectorielle des images hyperspectrales est tentante. On peut voir une image hyperspectrale comme une collection de spectres. Si deux pixels de l’image correspondent au même objet au sol, les spectres obtenus pour ces deux pixels seront les mêmes (au bruit près). La notion de codebook apparaît naturellement : on identifie les éléments qui sont présents dans l’image, on leur affecte un code. Il suffit ensuite de garder en mémoire le codebook et la répartition de ces codes dans l’image.
La quantification vectorielle suit ce principe. Divers travaux sont en cours sur la quantification vectorielle pour la compression des images hyperspectrales au sein de la Canadian Space Agency [Qia00,Qia04], mais également dans d’autres équipes [Mot03,Rya97,Rya00]. Les taux de compression visés sont très importants, de l’ordre de 100, et introduisent une distorsion importante sur les images [Qia04]. La distorsion en terme d’influence sur une application de type classification est généralement faible.
Un système basé sur une classification à bord est utilisé pour le satellite Nemo sur Cois (Annexe E.2.8). Ce système, nommé Orasis (Optical Real-time Adaptive Signature Identification System), permet d’obtenir des taux de compression de l’ordre de 30 tout en préservant de bonnes performances pour une application de classification [Bow00].
Dans le cas de compression bord où l’application n’est pas forcément connue au moment de l’acquisition des données, il est délicat d’utiliser un système de compression introduisant de telles distorsions. Pour ces raisons, l’attention se portera plutôt sur des compresseurs à base d’ondelettes introduisant une distorsion faible des données.
1.3.2.2 Codage par transformée
Divers travaux ont été réalisés avec différentes transformées notamment au niveau spectral : utilisation d’une transformée de Karhunen-Loeve (aussi appelée Analyse en Composantes Principales), une DCT, une analyse en composantes indépendantes (ACI), ondelettes …
Les principaux développements ont lieu autour de la transformée en ondelettes. En effet, la transformée en ondelettes a montré de bonnes capacités de décorrélation dans un but de compression sur les images réelles. Des implémentations avec une complexité limitée existent et il est également possible de faire un traitement au fil de l’eau.
Il existe principalement deux tendances pour tirer partie de la décorrélation après transformation en ondelettes. La première méthode qui est appliqué dans le standard JPEG 2000 [Tau02] est d’utiliser un codeur arithmétique pour coder les coefficients d’ondelettes. La seconde méthode tire partie du lien existant entre les coefficients de la transformée situés dans différentes sous-bandes (même si la corrélation est presque nulle). Ces dernières méthodes sont appelées codage par arbres de zéros. Les deux méthodes de codage par arbres de zéros les plus populaires sont EZW [Sha93] et SPIHT [Sai96].
Le seul compresseur ondelettes embarqué pour les images hyperspectrales est basé sur une adaptation de SPIHT [Lan00]. Cette adaptation ne tire pas entièrement partie de la structure 3D des images hyperspectrales, mais c’est une implémentation qui a fonctionné pour plusieurs missions lointaines, notamment pour la mission ROSETTA à destination de la comète 67P Churyumov-Gerasimenko.
1.3.3 Applications
Les applications de Détection, Reconnaissance, Identification (DRI) sur les images hyperspectrales ne fonctionnent pas de la même manière que sur les images classiques. Sur ces dernières, les traitements évolués sont effectués sur les pixels en tenant compte des pixels voisins. Les opérations de détection de contours et les méthodes évoluées de segmentation fonctionnent toutes en considérant le pixel dans son environnement. Au contraire, pour les applications hyperspectrales, l’accent est mis sur l’identification du spectre. Les applications actuelles fonctionnent donc essentiellement à partir de l’information spectrale. À plus long terme, il serait néanmoins intéressant de considérer des applications qui tiennent compte du spectre du pixel, mais également des pixels avoisinants.
Les images classiques sont souvent analysées par des photo-interprètes d’où l’importance de critères de qualité image en adéquation avec les spécificités de l’œil humain. Les récents développements sur les critères de qualité pour le domaine des images classiques mettent surtout l’accent sur les aspects visuels des images. Les distorsions structurées (effets de blocs…) auxquelles l’œil est particulièrement sensible devront donc être bien détectées. Les applications de segmentation, fonctionnant souvent par détection des frontières, seront également très sensibles à ces effets.
À cause de leur complexité, les images hyperspectrales sont généralement analysées par des systèmes automatiques, il est donc important de prendre en compte les dégradations qui affecteront spécifiquement ce type de systèmes. Les critères de qualité évolués basés sur les critères visuels ne sont pas adaptés, des critères de qualité valides pour ces systèmes doivent donc être développés.
L’accent devra être mis sur la détection des distorsions du spectre qui pourraient produire une chute dans les performances des applications. Le prochain chapitre propose des critères qualité permettant de relier les dégradations (causées par exemple par les algorithmes de compression) aux performances des applications des images hyperspectrales.